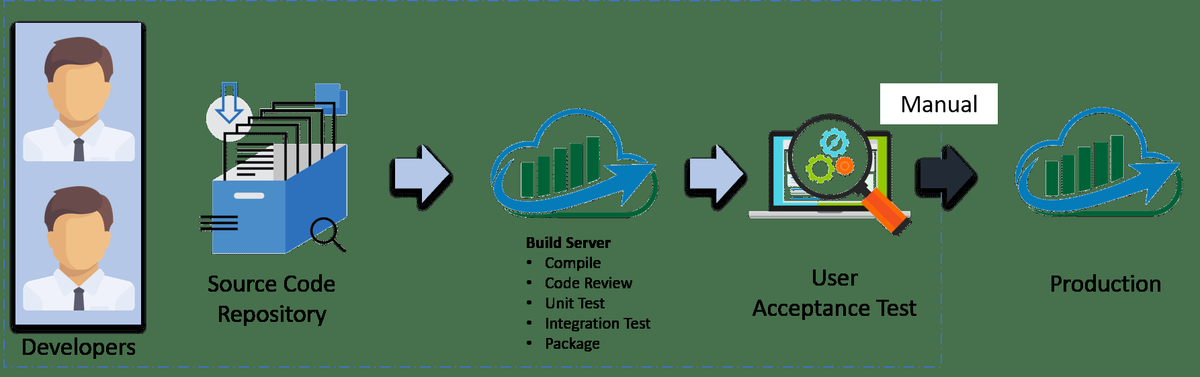
Tanggung Jawab Admin Hadoop
Blog di tanggung jawab Admin Hadoop ini membahas ruang lingkup administrasi Hadoop. Pekerjaan administrator Hadoop sangat diminati, jadi pelajari Hadoop sekarang!

Blog di tanggung jawab Admin Hadoop ini membahas ruang lingkup administrasi Hadoop. Pekerjaan administrator Hadoop sangat diminati, jadi pelajari Hadoop sekarang!
Apache Spark telah muncul sebagai perkembangan hebat dalam pemrosesan data besar.
Apache Hadoop 2.x terdiri dari peningkatan signifikan atas Hadoop 1.x. Blog ini membahas tentang Federasi Arsitektur Cluster Hadoop 2.0 dan komponennya.
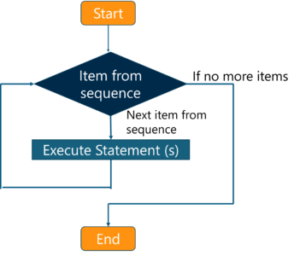
Ini memberikan wawasan tentang penggunaan pelacak Pekerjaan
Apache Pig memiliki beberapa fungsi standar. Posting berisi langkah-langkah yang jelas untuk membuat UDF di Apache Pig. Di sini kodenya ditulis dalam Java dan membutuhkan Pig Library
Ada arsitektur Penyimpanan HBase terdiri dari banyak komponen. Mari kita lihat fungsi dari komponen-komponen ini dan ketahui bagaimana data ditulis.
Apache Hive adalah paket Data Warehousing yang dibangun di atas Hadoop dan digunakan untuk analisis data. Hive ditargetkan untuk pengguna yang terbiasa dengan SQL.
Penerapan Apache Spark dengan Hadoop dalam skala besar oleh perusahaan-perusahaan terkemuka menunjukkan keberhasilan dan potensinya dalam hal pemrosesan waktu nyata.
Ketersediaan Tinggi NameNode adalah salah satu fitur terpenting dari Hadoop 2.0 NameNode High Availability dengan Quorum Journal Manager digunakan untuk berbagi log edit antara Active dan Standby NameNodes.
Tanggung jawab pekerjaan pengembang Hadoop mencakup banyak tugas Tanggung jawab pekerjaan tergantung pada domain / sektor Anda Peran ini mirip dengan Pengembang Perangkat Lunak
Model data Hive berisi komponen berikut seperti Database, Tabel, Partisi dan Bucket atau cluster. Hive mendukung tipe primitif seperti Integer, Float, Doubles, dan Strings.
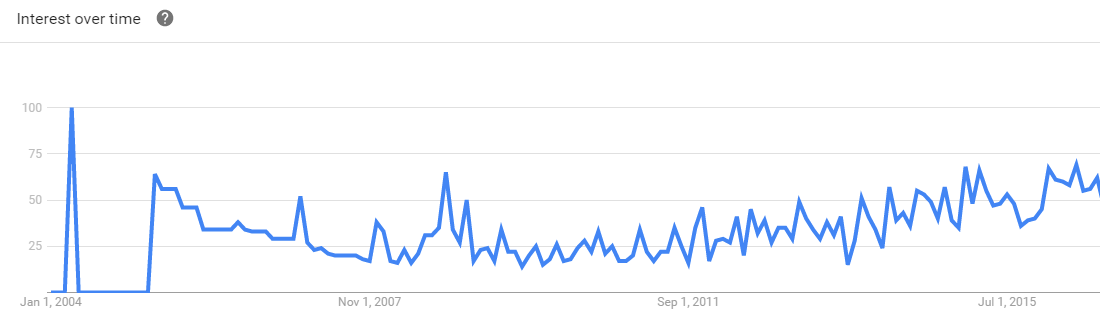
4 alasan untuk meningkatkan ke Hadoop 2.0 ini berbicara tentang pasar kerja Hadoop dan bagaimana hal itu dapat membantu Anda mempercepat karier dengan membuat Anda terbuka terhadap peluang kerja yang besar.
Di blog ini, kami akan menjalankan contoh Hive and Yarn di Spark. Pertama, buat Hive and Yarn di Spark, lalu Anda dapat menjalankan contoh Hive and Yarn di Spark.
Tujuan dari blog ini adalah untuk mempelajari cara mentransfer data dari database SQL ke HDFS, cara mentransfer data dari database SQL ke database NoSQL.
Pengembang Bersertifikat Cloudera untuk Apache Hadoop (CCDH) adalah pendorong bagi karier seseorang. Postingan ini membahas tentang manfaat, pola ujian, panduan belajar dan referensi yang bermanfaat.
Blog ini memberikan gambaran umum tentang arsitektur Ketersediaan Tinggi HDFS dan cara mengatur serta mengonfigurasi klaster Ketersediaan Tinggi HDFS dalam langkah-langkah sederhana.
Apache Kafka terus menjadi populer dalam hal Analisis Real-Time. Berikut ini sekilas dari sudut pandang karier, membahas peluang karier dan tuntutan pekerjaan.
Apache Kafka menyediakan throughput tinggi & sistem perpesanan yang dapat diskalakan sehingga populer dalam analitik waktu nyata. Pelajari bagaimana tutorial Apache kafka dapat membantu Anda
Posting blog ini membahas lebih dalam tentang Pig dan fungsinya. Anda akan menemukan demo bagaimana Anda dapat bekerja di Hadoop menggunakan Pig tanpa ketergantungan pada Java.
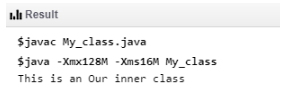
Blog ini membahas prasyarat untuk mempelajari Hadoop, dasar-dasar Java untuk Hadoop & menjawab 'apakah Anda memerlukan Java untuk mempelajari Hadoop' jika Anda tahu Pig, Hive, HDFS.